Current Education Systems
Education has traditionally been approached using a “one size fits all” system. This traditional system has been heavily criticized in recent years for being unable to address the demands of each student. However, due to a lack of solutions, the “one size fits all” education system is still being used nowadays even with the advancement of technology. he global education systems are moving in the direction of a more individualized, student-centered strategy where the traditional "one size fits all" approach has been moved to the Smart Learning Environment. This learning environment can be achieved through personalized or adaptive learning to improve the current educational system. The Educational Recommendation System that implements AI and data science methodology has been believed as one of the ways to achieve personalized adaptive learning.
Problems in Educational Recommendation Systems
Currently, most of the conventional artificial intelligence models used in educational recommendation systems do not achieve high enough performance to meet the personal needs of the learners. Current educational recommendation systems have several notable limitations namely cold-start problems and sparsity problems associated with the collaborative filtering approach, limited understanding of learning item features associated with the content-based approach and complexity of implementation which is associated with the knowledge-based approach and hybrid-based approach. With this additional limitation, the current recommendation system often did not achieve optimal performance.
Education Data
The chosen dataset used in this project is MOOCCube dataset which later requires some pre-processing such as entities and features selection where the important entities and features will be selected while unnecessary entities and features will be ignored; data cleaning, the mandatory data pre-processing techniques; data sampling, to make the computational cost less expensive; data transformation, transform the data into usable form; data integration where several features and entities will be combined forming desired input data; data encoding, to transform categorical data into numerical value and data splitting for model training and testing. The dataset and more explanation of the dataset can be found in the MOOCCube.
Pre-processing and Modelling
There are total 6 models of Generative Adversarial Networks (GANs) and its variants used which are GANs, MDGANs, Multi-GANs, Multi-MDGANs together with the baseline model which is collaborative filtering and content-based filtering. Each model use different method of data preparation.
GANs
GANs is a type of neural network used for generative modeling. It consists of two networks: a generator and a discriminator. The generator creates new data samples, while the discriminator tries to distinguish between real and generated samples. They are trained together in an adversarial manner, where the generator tries to fool the discriminator and the discriminator tries to become better at distinguishing real from fake. This competition leads to the generator learning to create increasingly realistic samples, making GANs useful for the main task in this project which is course recommendation. A detailed explanation of the GANs framework as well as the source code can be found in the model/GANs directory.
Multi-GANs
Similar to GANs, Multi-GANs uses the same principle as GANs. However, Multi-GANs uses multiple GANs models to predict the top k course. The number of GANs models used is similar to the number of recommendations (k). In this project, all the recommendation is based on five recommendations which means five models of GANs were used to recommend five courses. Multi-GANs are a powerful extension of the GANs framework, allowing for a more nuanced and diverse generation of data by leveraging the strengths of multiple generative models working together. A detailed explanation of the Multi-GANs framework as well as the source code can be found in the model/Multi-GANs directory.
MDGANs
MDGAN is a variation of the traditional GANs architecture that employs multiple discriminators. The main idea behind MDGAN is to improve the stability and quality of generated samples by using multiple discriminators to provide feedback to the generator. In MDGAN, there are multiple discriminators, each focusing on a different aspect or feature of the generated samples. In this case, three discriminators were used. Discriminator one will focus on the course sequence, discriminator two will focus on the school sequence, and discriminator three will focus on the teacher sequence. Using multiple discriminators can help the generator learn more effectively by receiving feedback from different perspectives. MDGANs are often more stable during training compared to traditional GANs, as the generator is trained to fool multiple discriminators simultaneously. A detailed explanation of the MDGAN framework as well as the source code can be found in the model/MDGAN directory.
Multi-MDGANs
Similar to MDGANs, Multi-MDGAN uses the same principle as MDGAN. However, Multi-MDGAN uses multiple MDGAN models to predict the top k course. The number of MDGAN models used is similar to the number of recommendations (k). In this project, all the recommendation is based on five recommendations which means five models of MDGAN were used to recommend five courses. Multi-MDGANs extend the idea of using multiple discriminators in a GANs setup to multiple MDGANs, allowing for a more complex and nuanced generation of data by leveraging the strengths of multiple generative models working together. A detailed explanation of the Multi-MDGAN framework as well as the source code can be found in the model/Multi-MDGAN directory.
Collaborative Filtering
Collaborative Filtering (CF) is a technique used in recommendation systems to predict a user's preferences for items based on the preferences of other users. The basic idea behind collaborative filtering is that if two users have similar preferences for a set of items, they are likely to have similar preferences for other items as well. A detailed explanation of the CF framework as well as the source code can be found in the model/CF directory.
Content-based Filtering
Content-Based (CB) recommendation is a technique used in recommendation systems to recommend items to users based on the features or characteristics of the items and the preferences of the users. Unlike collaborative filtering, which relies on the preferences of other users, content-based recommendation focuses on the attributes of the items themselves. A detailed explanation of the CB framework as well as the source code can be found in the model/CB directory.
Evaluation
There are four evaluation metrics used in this project which are Mean Average Precision (MAP), Hit Ratio (HR), Mean Reciprocal Rank (MRR), and Normalized Discounted Cumulative Gain (NDCG). Since the output of the recommendation model is in the form of the top five recommendations, therefore, all the mentioned metrics will become MAP@5, HR@5, MRR@5, and NDGC@5. Using these metrics provides valuable insight into system functionality and its impact on learners. By examining these metrics, it will give a better understanding of the system’s ability to meet individual needs and improve each user’s learning experience.
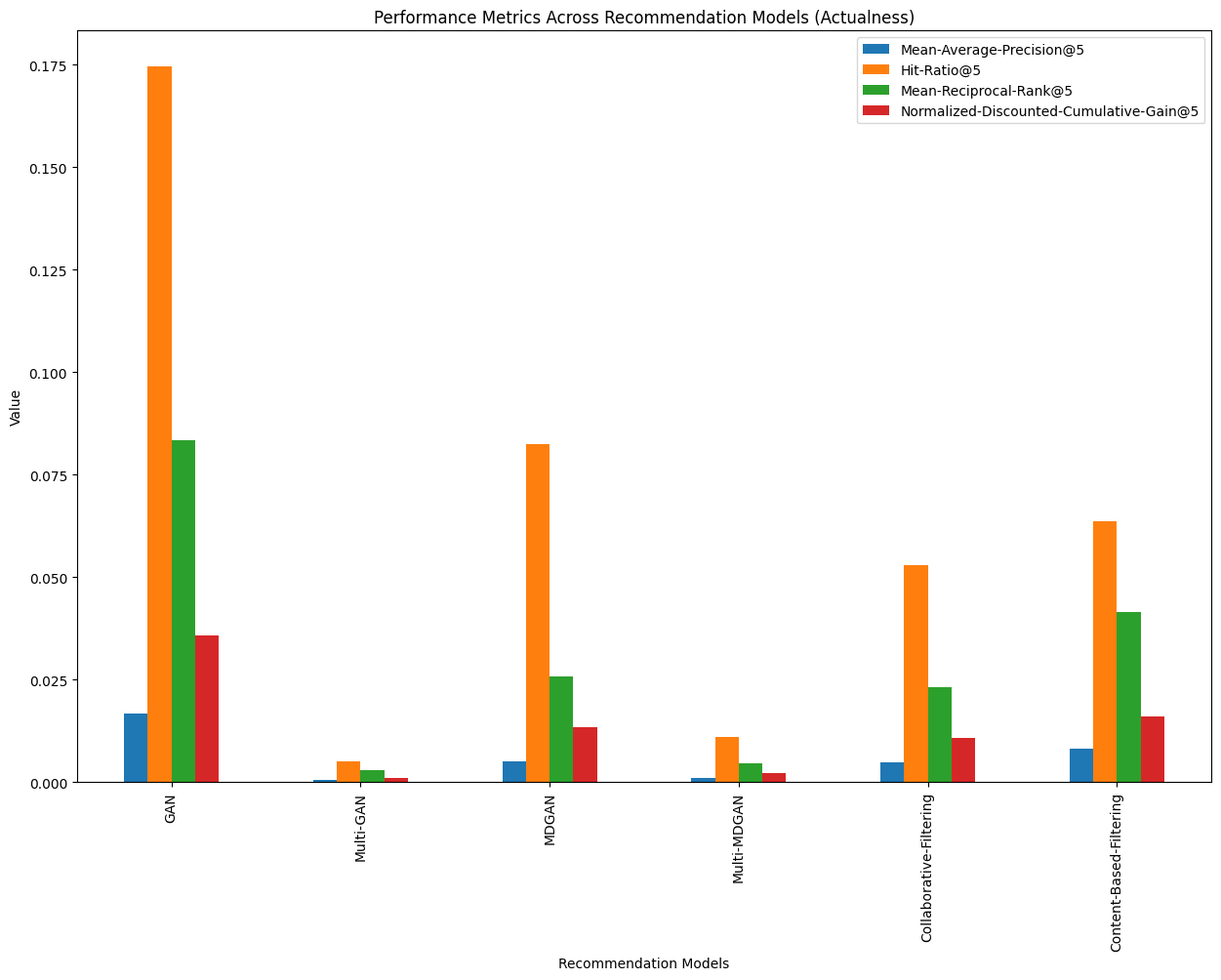
Overall, the GAN model outperforms all models in all performance metrics. It shows the highest value of all performance metrics. This shows the GAN model has a great degree of ability to provide better recommendations compared to the old technique of CF and CB. On the other hand, the Multi-GAN has shown the worst performance across all metrics, the worst performance is then followed by Multi-MDGAN. This indicates that the "Multi" framework of GAN is not a suitable model for this task. The MDGAN model has shown some degree of ability in the recommendations task which this model outperforms the CF model in all metrics. However, in comparison with CB, the MDGAN model manages to outperform the CB model only in the HR@5 metric. So it can be seen that the MDGAN model has a great degree in recommending accurate courses compared to baseline models as shown by HR@5 metrics. But the overall performance of MDGAN is still below the CB model and it is still very far from the winner of this task, the GAN model.
Data Product
The data product was created by using a third-party tool, Anvil to build a website-based recommendation system. The recommendation engine includes all the models used in this project including generative models and baseline models. In this case, there are six different options for recommendation engines which are Generative Adversarial Networks, Multiple Generative Adversarial Networks, Multi-Discriminators Generative Adversarial Networks, Multiple Multi-Discriminators Generative Adversarial Networks, Collaborative Filtering, and Content-Based Filtering.
Contribution
The successful implementation of generative AI in educational recommendation systems makes a significant contribution to this field. The main contribution of this project is to develop an educational recommendation system based on generative models. To the best of my knowledge, this project first introduces GAN to the recommendation task in the education field. Next, the project identified the generative model has shown to have a high degree of performance as a recommendation engine. The results showed that the use of generative models especially the GAN model increased up to 200% in all metrics which is an extremely significant improvement over baseline models. This contribution advances the field of educational recommendation systems providing a new approach to enhancing the performance of the recommendation system, with potential applications in educational platforms or educational institutions.
Conclusion
In conclusion, the project highlights the transformative potential of generative artificial intelligence (AI) in revolutionizing personalized learning in education. By implementing generative models in educational recommendation systems, significant improvements in recommendation accuracy and relevance were achieved. The project underscores the importance of continued research and innovation in leveraging AI technologies to create adaptive and personalized learning environments, ultimately enhancing the educational experience for students worldwide.