The Classical Music
Classical music, rich in history and emotion, continues to inspire despite its decline in popularity. With the advent of Generative AI, classical music is evolving in exciting ways. AI can analyze and recreate the styles of great composers like Bach and Mozart, offering fresh compositions and expanding creative possibilities for modern musicians. This technology helps introduce classical music to new audiences while posing challenges in ensuring originality and defining the role of human composers in the AI-driven creative process.
Problems in Classical Music
Classical music faces a decline in popularity, limited access to skilled composers, and challenges in engaging modern audiences. Traditional methods may not fully explore new creative possibilities, and ensuring originality in compositions is difficult. AI can address these issues by revitalizing classical music with innovative compositions, democratizing compositional tools, preserving classical heritage, streamlining production processes, and creating engaging educational experiences for new listeners.
Music Data
The dataset used in this project was obtained from kaggle. Where the dataset consists of classical piano midi files containing compositions of 19 famous composers scraped from piano-midi website. From all famous composers, this project utilizes classical music from only one composer which is known as Chopin. The reason why only one composer was used is due to resource limitation, cost, and time efficiency.
EDA
The data underwent a sampling process where only Chopin's music will be chosen. There are two types of EDA, the first type of EDA is directly toward the exploration of the music composition itself without data preprocessing where the music sheet and audio are produced to get a better understanding of the music on how music sounds and how the music notes and durations looks like.
Music Composition

The process continued with the data preprocessing where each of the Chopin-composed music underwent clef splitting where the treble and bass clef were separated. Each of the clefs was undergone the music element extraction where the notes, chords, and durations were extracted for the data frame construction. There are two total data frames were created which are the treble data frame and bass data frame, each representing the treble clef and bass clef respectively. Each data frame consists of two features where the first feature is the notes and chords while the second feature is durations. The chords and notes were extracted based on their pitch frequency while the durations were extracted based on the durations type. Each of the data frames underwent the second type of EDA which is more toward data analytics. The EDA includes univariate analysis, multivariate analysis, and outliers analysis.
Univariate Analysis
Bass Clef
Pitch Frequency
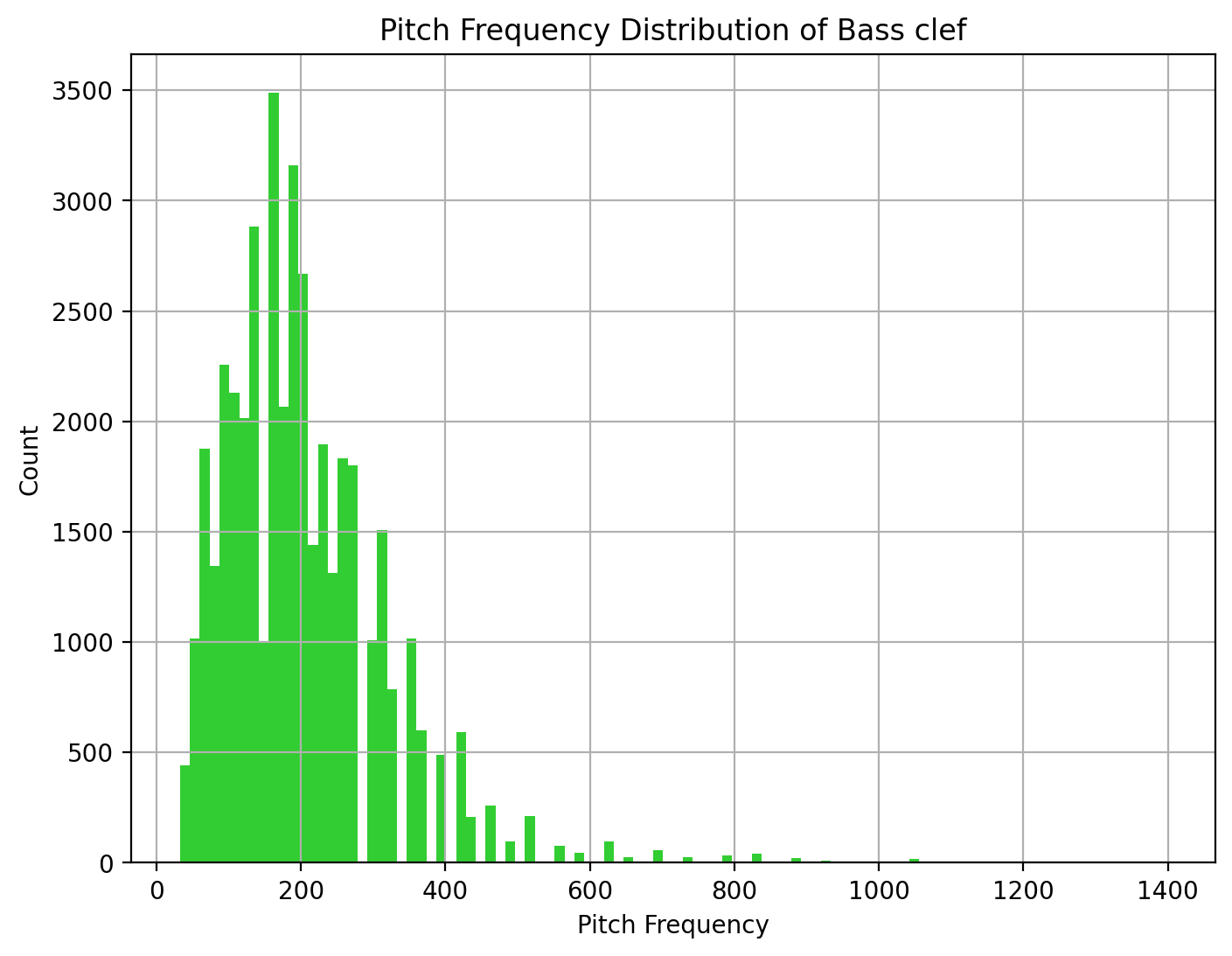
The distribution of pitch frequency is positively skewed with the modes around 160 hz. The majority of the chords and notes used are in the frequencies of 50 to 300 hz. While chords and notes with frequencies around 500 hz and above can be seen as minority chords and notes used in the Chopin-composed music.
Duration
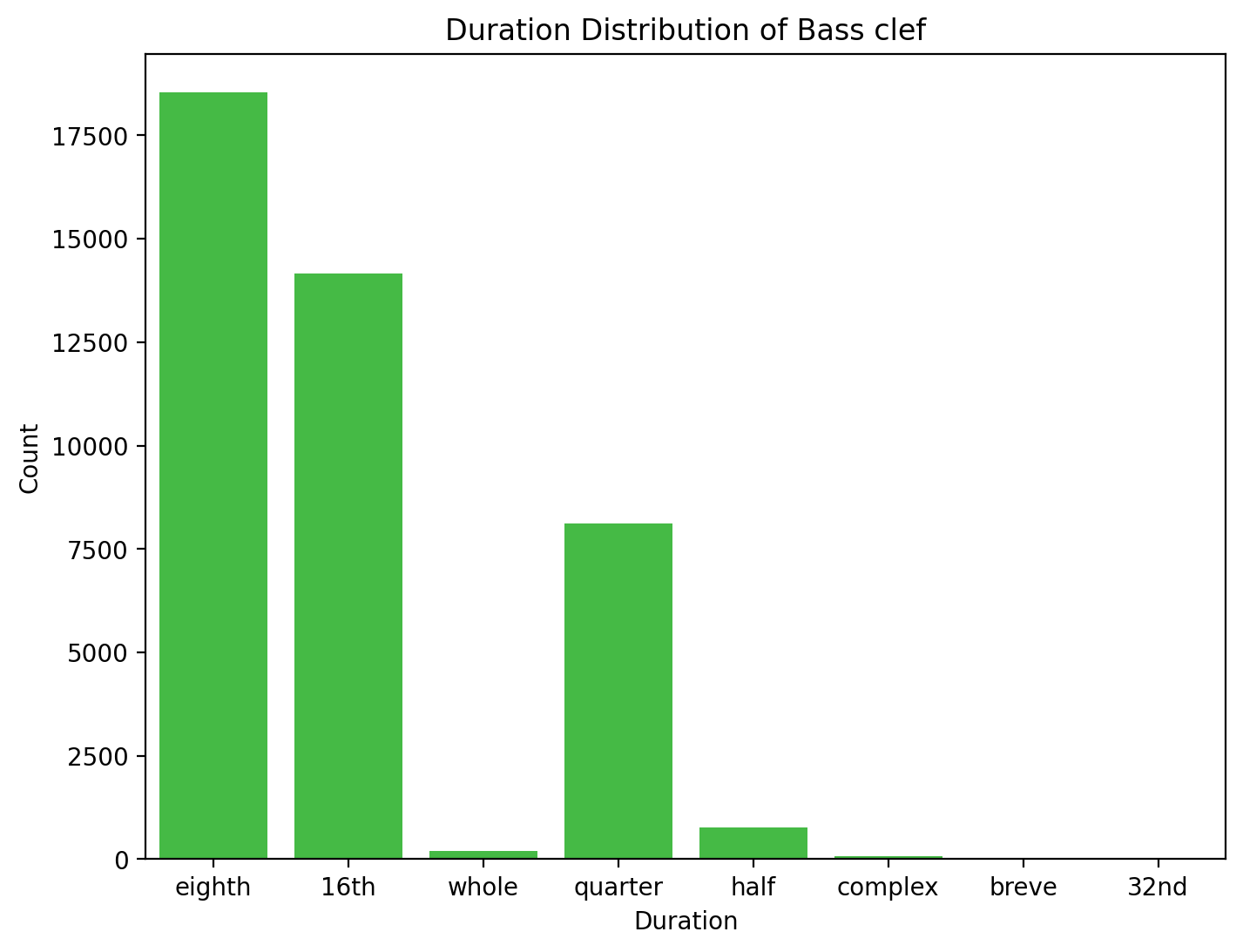
The majority of the durations used are 8th notes with around 17500 counts followed by 16th notes with around 14000 counts. The quarter notes are in the third position with around 7500 counts. Other than the mentioned durations which are whole note, half note, complex note, breve note, and 32nd note are the minority durations in the Chopin-composed music.
Treble Clef
Pitch Frequency
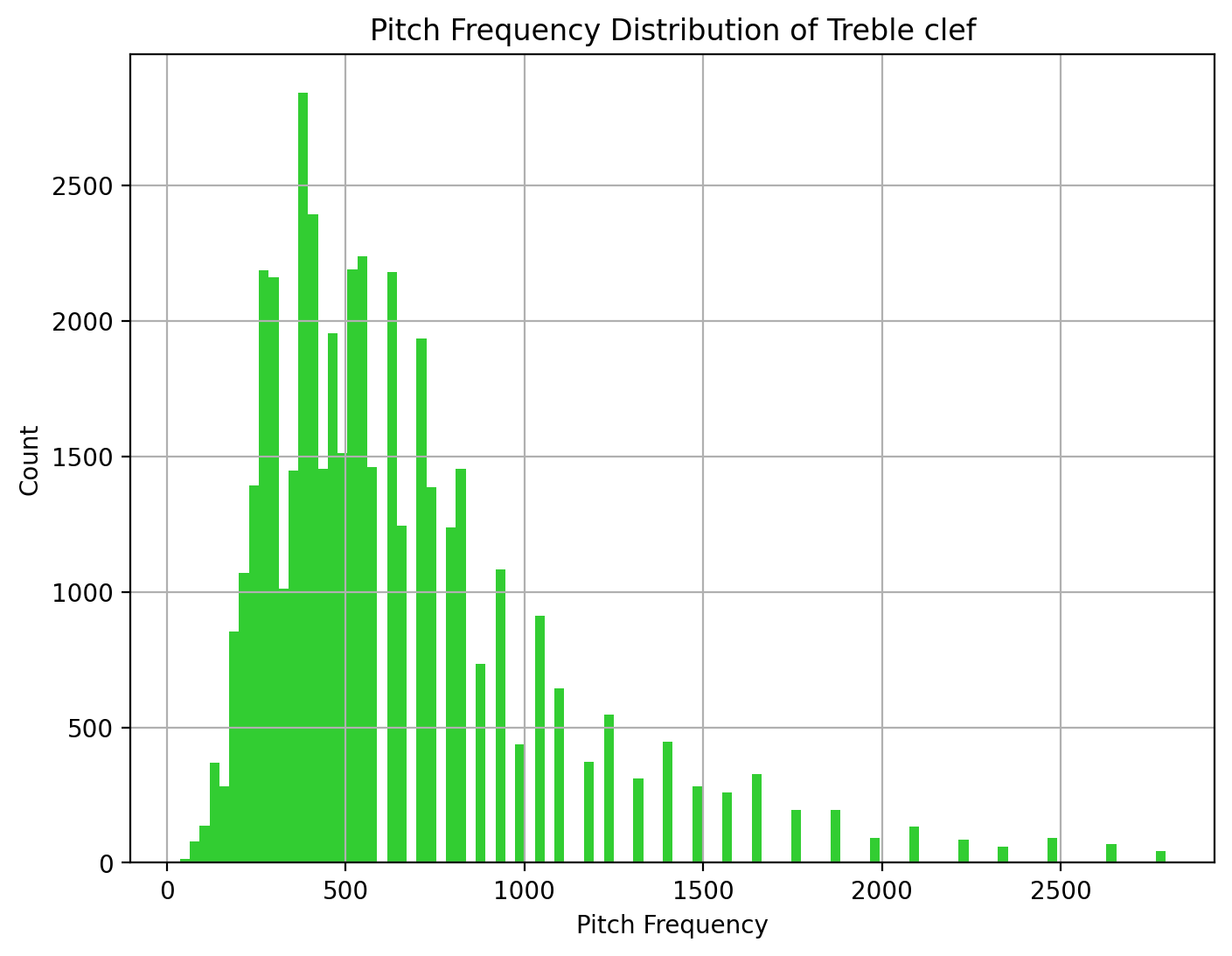
The distribution of pitch frequency is positively skewed with the modes around 350 hz. The majority of the chords and notes used are in the frequencies of 200 to 1300 hz. While chords and notes with frequencies around 1500 hz and above can be seen as minority chords and notes used in the Chopin-composed music.
Duration
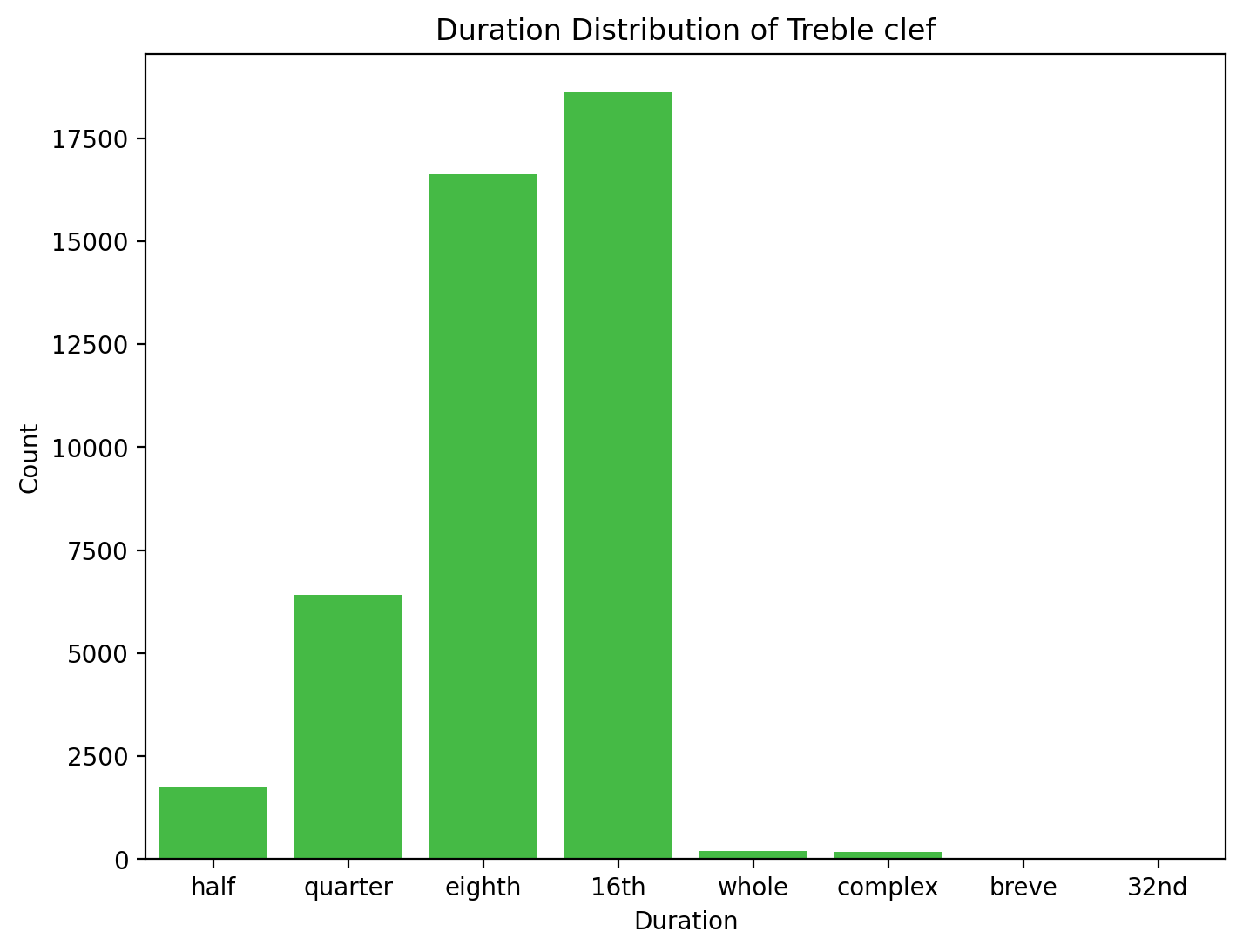
The majority of the duration used is 16th notes followed by 8th note. The quarter note is in the third position with around 6500 counts. Other than the mentioned durations which are whole note, half note, complex note, breve note, and 32nd note are the minority durations in Chopin composed music.
Pre-processing and Modelling
There are so many generative models available which can be used in this project. However, among all the generative models, only 4 models will be used which are the autoregressive model known as Recurrent Neural Networks (RNNs) by using Long Short-Term Memory (LSTM) architecture, Variational AutoEncoders (VAEs), Generative Adversarial Networks (GANs) and large language model of Generative Pretrained Transformer (GPT). Another model used in this project is a fusion model which is a combination of three different generative model architecture. The fusion model utilizing the RNNs of Gate Recurrent Units (GRUs) architecture combines VAEs architecture together with GANs architecture. Each of the models requires a different representation of the data, therefore, different preprocessing was applied to the data for each model.
Autoregressive Model - LSTM
LSTM is a type of neural network designed to handle sequence data by maintaining long-term dependencies. It does this by using a memory cell that can store information, along with gates that control the flow of information into and out of the cell. This allows LSTM networks to learn patterns in sequences and make predictions based on them, making them useful for the main task in this project which is classical music recomposition. A detailed explanation of the LSTM framework as well as the source code can be found in the model/lstm directory.
AutoEncoders Model - VAEs
VAEs is a type of neural network used for generative modeling. It learns to encode input data into a lower-dimensional latent space and then decode it back to the original input. VAEs are trained to maximize the likelihood of the observed data while also maximizing the mutual information between the latent variables and the data. This allows them to generate new data samples that resemble the training data, making them useful for the main task in this project which is classical music recomposition. A detailed explanation of the VAEs framework as well as the source code can be found in the model/vae directory.
Generative Adversarial Networks - GANs
GANs is a type of neural network used for generative modeling. It consists of two networks: a generator and a discriminator. The generator creates new data samples, while the discriminator tries to distinguish between real and generated samples. They are trained together in an adversarial manner, where the generator tries to fool the discriminator and the discriminator tries to become better at distinguishing real from fake. This competition leads to the generator learning to create increasingly realistic samples, making GANs useful for the main task in this project which is classical music recomposition. A detailed explanation of the GANs framework as well as the source code can be found in the model/gan directory.
Fusion Model - RNNs-VAEs-GANs

A fusion generative model that combines GRUs, VAEs, and GANs elements would be a complex architecture aimed at capturing the strengths of each component. The GRUs component will be used for sequence modeling. GRUs are a type of RNNs that can capture long-range dependencies in sequences, making them suitable for tasks where the context of previous elements is important. While the VAEs component would handle the latent space modeling. It would encode input data into a latent space representation, which can then be decoded back into the original data. VAEs are useful for learning meaningful representations of data and generating new samples that resemble the training data. Finally, the GANs component would add a competitive training mechanism to improve the realism of the generated samples. The generator part of the GANs would likely be integrated with the VAEs decoder, generating samples from the learned latent space. The discriminator would then provide feedback to both the generator and the VAEs on the realism of the generated samples. In this fusion model, the GRUs would help capture the sequential dependencies in the data, the VAEs would learn a meaningful latent space representation, and the GANs would improve the quality of the generated samples. By combining these components, the model could potentially achieve better performance than using any one component alone. A detailed explanation of the fusion model framework as well as the source code can be found in the model/fusion directory.
Large Language Model - GPT
GPT is a type of deep learning model based on the transformer architecture. It is designed for natural language processing tasks such as text generation, translation, and question answering. However, since text generation is a sequence data and the music also is a sequence data. The GPT should be able to model music data, in a way that captures the structure and patterns of music. GPT is "pre-trained" on a large corpus of musical data, which allows it to learn the nuances of music elements and context. This pre-training is followed by fine-tuning specific tasks to further improve performance. A detailed explanation of the GPT framework as well as the source code can be found in the model/gpt directory.
Results & Evaluation
There are three pieces of music generated for each model. The first music was generated by using the key of C major and a tempo of 90 bpm. The second music was generated by using the key of A minor and a tempo of 60 bpm. Finally, the final music was generated by using the key of E minor and a tempo of 120 bpm. All the music generated uses a time signature of 4/4 which is the most common time signature. All the pieces of music was evaluated by the audience and subject matter expert (musician).
LSTM
Results
Key: C Major, Tempo: 90 Bpm
Key: A Minor, Tempo: 60 Bpm
Key: E Minor, Tempo: 120 Bpm
VAEs
Results
Key: C Major, Tempo: 90 Bpm
Key: A Minor, Tempo: 60 Bpm
Key: E Minor, Tempo: 120 Bpm
GANs
Results
Key: C Major, Tempo: 90 Bpm
Key: A Minor, Tempo: 60 Bpm
Key: E Minor, Tempo: 120 Bpm
RNNs-VAEs-GANs
Results
Key: C Major, Tempo: 90 Bpm
Key: A Minor, Tempo: 60 Bpm
Key: E Minor, Tempo: 120 Bpm
GPT
Results
Key: C Major, Tempo: 90 Bpm
Key: A Minor, Tempo: 60 Bpm
Key: E Minor, Tempo: 120 Bpm
Overall Evaluation
The LSTM model, while capable of generating a structured music sequence, often lacked of coherent music sequence in terms of synchronization of treble and bass clef. The VAEs model, on the other hand, was successful in generating diverse compositions but struggled with maintaining the musical structure which caused a disorderliness and randomness of music elements generated. The GANs model also has a similar limitation to the VAEs which is struggled with maintaining music structure. The RNNs-VAEs-GANs fusion model attempted to combine the strengths of the VAEs and GANs models with an additional RNNs layer for improved musical structure. While it showed improvements over individual models, it still faced challenges in balancing coherence, diversity, and maintaining musical structure. Despite not being trained on a large corpus of language, the GPT model outperformed all other models in our evaluation. It is able to generate highly coherent, diverse, musical structures and musically pleasing compositions. Its transformer architecture demonstrated a remarkable ability to capture the nuances of classical music, producing compositions that were indistinguishable from human-composed pieces.
Establish Classical Music and AI generated Music
Established classical music, crafted over centuries by master composers, embodies a profound legacy of artistic expression and cultural significance, characterized by intricate melodies and harmonies that resonate with deep emotional and intellectual depth. In contrast, AI-generated music represents a novel frontier, leveraging machine learning and algorithms to produce compositions that, while lacking the human touch and historical context of classical masterpieces, offer a fresh perspective and potential for innovation. While AI-generated music may not yet match the depth and complexity of classical compositions, it presents a fascinating evolution of musical creativity, sparking debates about the nature of artistry, the impact of technology on music, and the boundaries of musical expression.
Conclusion
In conclusion, this study has explored the use of generative AI for recomposing classical music, focusing on developing algorithms that can produce music similar to classical compositions. Through the evaluation of various generative AI algorithms, I have identified those capable of creating music that is not only pleasant but also approaches the characteristics of classical music especially music generated by GPT. Additionally, by comparing AI-generated classical music compositions with established works in the classical repertoire, I have gained insights into the artistic expression of these compositions, as evaluated by both musicians and audiences. This study highlights the potential of generative AI in music composition, offering new avenues for creative exploration and pushing the boundaries of musical expression.